ในบทความนี้เราจะเริ่มการอภิปรายในหัวข้อที่น่าสนใจอย่างยิ่ง - การใช้สถิติเพื่อการวิเคราะห์ข้อมูลข้อความ โปรดทราบว่าการใช้สถิติสำหรับการวิเคราะห์ข้อความเป็นงานแบบดั้งเดิม
ก่อนอื่นเราจะนำเสนอข้อเท็จจริงที่น่าสนใจเกี่ยวกับความถี่ของการเกิดตัวอักษรและการรวมกันในภาษาต่างๆ (ดูรายละเอียดเพิ่มเติมในหนังสือ) ในบทความต่อๆ ไป เราจะแสดงวิธีใช้วิธีการวิเคราะห์และการแสดงภาพกราฟิกที่ซับซ้อนมากขึ้น
ลักษณะความถี่ของข้อความ
ดังนั้นข้อความจึงประกอบด้วยคำคำของตัวอักษร จำนวนตัวอักษรที่แตกต่างกันในแต่ละภาษามีจำนวนจำกัด และสามารถแสดงรายการตัวอักษรได้ ลักษณะสำคัญของข้อความคือการซ้ำตัวอักษร คู่ตัวอักษร (ไดแกรม) และโดยทั่วไป ม-ตกลง ( ม-gram) ความเข้ากันได้ของตัวอักษรระหว่างกัน การสลับสระและพยัญชนะ และอื่นๆ เป็นที่น่าสังเกตว่าลักษณะเหล่านี้ค่อนข้างคงที่ เราทิ้งคำถามว่า "ทำไม" ไว้เบื้องหลัง
การใช้งานระบบ สถิติคุณสามารถตรวจสอบรูปแบบเหล่านี้ได้ เช่น ในข้อความทางอินเทอร์เน็ต
แนวคิดคือการนับจำนวนครั้งของแต่ละรายการ n มเป็นไปได้ ม-gram ในข้อความธรรมดาที่ยาวเพียงพอ ต=เสื้อ 1 เสื้อ 2 …t ลซึ่งประกอบด้วยตัวอักษร ( ก 1 , 2 , ... , น). ขณะเดียวกันติดต่อกัน ม- กรัมของข้อความ:
เสื้อ 1 เสื้อ 2 ...เสื้อ ม , เสื้อ 2 เสื้อ 3 ... เสื้อ m+1 , ..., ผม-m+1 เสื้อ l-m+2 ...t l.
ถ้า - จำนวนครั้งที่เกิดขึ้น ม-กรัม i1 i2 ...ฉันในข้อความ ต, ก ล– จำนวนนับทั้งหมด ม-gram แล้วประสบการณ์แสดงว่ามีขนาดใหญ่เพียงพอ ลความถี่
สำหรับสิ่งนี้ ม- กรัมต่างกันเล็กน้อย
ด้วยเหตุนี้ ความถี่สัมพัทธ์ (1) จึงถือเป็นค่าประมาณของความน่าจะเป็น ป (i1 i2 ...ฉัน) การปรากฏตัวของสิ่งนี้ ม-grams ในตำแหน่งที่เลือกแบบสุ่มในข้อความ (แนวทางนี้ใช้ในการกำหนดความน่าจะเป็นทางสถิติ)
ด้านล่างนี้คือตารางความถี่ตัวอักษร (เป็นเปอร์เซ็นต์) สำหรับภาษายุโรปจำนวนหนึ่ง ข้อมูลที่นำมาจากหนังสือ
| ตัวอักษรของตัวอักษร | ภาษาฝรั่งเศส | เยอรมัน | ภาษาอังกฤษ | สเปน | ภาษาอิตาลี |
|---|---|---|---|---|---|
| ก | 7.68 | 5.52 | 7.96 | 12.90 | 11.12 |
| บี | 0.80 | 1.56 | 1.60 | 1.03 | 1.07 |
| ค | 3.32 | 2.94 | 2.84 | 4.42 | 4.11 |
| ดี | 3.60 | 4.91 | 4.01 | 4.67 | 3.54 |
| อี | 17.76 | 19.18 | 12.86 | 14.15 | 11.63 |
| เอฟ | 1.06 | 1.96 | 2.62 | 0.70 | 1.15 |
| ช | 1.10 | 3.60 | 1.99 | 1.00 | 1.73 |
| ชม | 0.64 | 5.02 | 5.39 | 0.91 | 0.83 |
| ฉัน | 7.23 | 8.21 | 7.77 | 7.01 | 12.04 |
| เจ | 0.19 | 0.16 | 0.16 | 0.24 | - |
| เค | - | 1.33 | 0.41 | - | - |
| ล | 5.89 | 3.48 | 3.51 | 5.52 | 5.95 |
| ม | 2.72 | 1.69 | 2.43 | 2.55 | 2.65 |
| เอ็น | 7.61 | 10.20 | 7.51 | 6.20 | 7.68 |
| โอ | 5.34 | 2.14 | 6.62 | 8.84 | 8.92 |
| ป | 3.24 | 0.54 | 1.81 | 3.26 | 2.66 |
| ถาม | 1.34 | 0.01 | 0.17 | 1.55 | 0.48 |
| ร | 6.81 | 7.01 | 6.83 | 6.95 | 6.56 |
| ส | 8.23 | 7.07 | 6.62 | 7.64 | 4.81 |
| ต | 7.30 | 5.86 | 9.72 | 4.36 | 7.07 |
| ยู | 6.05 | 4.22 | 2.48 | 4.00 | 3.09 |
| วี | 1.27 | 0.84 | 1.15 | 0.67 | 1.67 |
| ว | - | 1.38 | 1.80 | - | - |
| เอ็กซ์ | 0.54 | - | 0.17 | 0.07 | - |
| ย | 0.21 | - | 1.52 | 1.05 | - |
| ซี | 0.07 | 1.17 | 0.05 | 0.31 | 1.24 |
ความแตกต่างบางประการของค่าความถี่ในตารางที่ระบุในแหล่งต่าง ๆ นั้นอธิบายได้จากข้อเท็จจริงที่ว่าความถี่นั้นไม่เพียงขึ้นอยู่กับความยาวของข้อความเท่านั้น แต่ยังขึ้นอยู่กับลักษณะของมันด้วย ตัวอย่างเช่น ในข้อความทางเทคนิค อักษรหายาก เอฟอาจกลายเป็นเรื่องธรรมดาได้เนื่องจากมีการใช้คำบ่อยๆ เช่น ฟังก์ชัน, ดิฟเฟอเรนเชียล, การแพร่, สัมประสิทธิ์ ฯลฯ
ความเบี่ยงเบนที่ยิ่งใหญ่กว่าจากบรรทัดฐานในความถี่ของการใช้ตัวอักษรแต่ละตัวนั้นพบได้ในงานศิลปะบางชิ้นโดยเฉพาะในบทกวี ดังนั้นเพื่อกำหนดความถี่เฉลี่ยของตัวอักษรได้อย่างน่าเชื่อถือจึงขอแนะนำให้มีชุดข้อความต่าง ๆ ที่ยืมมาจากแหล่งต่าง ๆ อย่างไรก็ตามตามกฎแล้วการเบี่ยงเบนดังกล่าวไม่มีนัยสำคัญและสามารถละเลยการประมาณครั้งแรกได้
การแสดงความถี่ของตัวอักษรด้วยภาพจะได้รับจากแผนภาพเหตุการณ์ ดังนั้นสำหรับภาษาอังกฤษตามตารางแผนภาพดังกล่าวจะแสดงในรูปที่ 1 ในการสร้างมันเราใช้ระบบ สถิติ.

สำหรับภาษารัสเซีย ความถี่ (ตามลำดับจากมากไปน้อย) ของตัวอักษรที่ระบุ อีค โย่, ขกับ คอมเมอร์สันต์และยังมีเครื่องหมายเว้นวรรค (-) ระหว่างคำด้วย แสดงไว้ในตารางต่อไปนี้ (ดู)
| -
0.175 | เกี่ยวกับ
0.090 | ของเธอ
0.072 | ก
0.062 |
| และ
0.062 | ต
0.053 | เอ็น
0.053 | กับ
0.045 |
| ร
0.040 | ใน
0.038 | ล
0.035 | ถึง
0.028 |
| ม
0.026 | ดี
0.025 | ป
0.023 | ยู
0.021 |
| ฉัน
0.018 | ย
0.016 | ซี
0.016 | ขข
0.014 |
| บี
0.014 | ช
0.013 | ชม
0.012 | ย
0.010 |
| เอ็กซ์
0.009 | และ
0.007 | ยุ
0.006 | ช
0.006 |
| ค
0.004 | สช
0.003 | อี
0.003 | เอฟ
0.002 |
จากตารางเราได้แผนภาพความถี่ต่อไปนี้ (รูปที่ 2)

มีกฎช่วยในการจำสำหรับการจดจำตัวอักษรสิบตัวที่พบบ่อยที่สุดของตัวอักษรรัสเซีย ตัวอักษรเหล่านี้ประกอบขึ้นเป็นคำไร้สาระ HAY คุณยังสามารถแนะนำวิธีการจำตัวอักษรทั่วไปในภาษาอังกฤษที่คล้ายกันได้ เช่น การใช้คำว่า TETRIS-HONDA (ดูตาราง)
ลักษณะความถี่ของบิ๊กแกรม ไตรแกรม และสี่กรัมของข้อความที่สื่อความหมายก็มีความเสถียรเช่นกัน
เรานำเสนอตารางความถี่บิ๊กแกรมสำหรับภาษารัสเซียและอังกฤษ (ตารางนี้ยืมมาจากหนังสือ) เพื่อความสะดวกจะแบ่งออกเป็นสี่ส่วนตามรูปแบบดังต่อไปนี้:
| ส่วนที่ 1 | ส่วนที่ 2 |
| ส่วนที่ 3 | ส่วนที่ 4 |
|
ส่วนที่ 1 |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ก | บี | ใน | ช | ดี | อี | และ | ซี | และ | ย | ถึง | ล | ม | เอ็น | เกี่ยวกับ | ป | |
| ก | 2 | 12 | 35 | 8 | 14 | 7 | 6 | 15 | 7 | 7 | 19 | 27 | 19 | 45 | 5 | 11 |
| บี | 5 | 9 | 1 | 6 | 6 | 2 | 21 | |||||||||
| ใน | 35 | 1 | 5 | 3 | 3 | 32 | 2 | 17 | 7 | 10 | 3 | 9 | 58 | 6 | ||
| ช | 7 | 3 | 3 | 5 | 1 | 5 | 1 | 50 | ||||||||
| ดี | 25 | 3 | 1 | 1 | 29 | 1 | 1 | 13 | 1 | 5 | 1 | 13 | 22 | 3 | ||
| อี | 2 | 9 | 18 | 11 | 27 | 7 | 5 | 10 | 6 | 15 | 13 | 35 | 24 | 63 | 7 | 16 |
| และ | 5 | 1 | 6 | 12 | 5 | 6 | ||||||||||
| ซี | 35 | 1 | 7 | 1 | 5 | 3 | 4 | 2 | 1 | 2 | 9 | 9 | 1 | |||
| และ | 4 | 6 | 22 | 5 | 10 | 21 | 2 | 23 | 19 | 11 | 19 | 21 | 20 | 32 | 8 | 13 |
| ย | 1 | 1 | 4 | 1 | 3 | 1 | 2 | 4 | 5 | 1 | 2 | 7 | 9 | 7 | ||
| ถึง | 24 | 1 | 4 | 1 | 4 | 1 | 1 | 26 | 1 | 4 | 1 | 2 | 66 | 2 | ||
| ล | 25 | 1 | 1 | 1 | 1 | 33 | 2 | 1 | 36 | 1 | 2 | 1 | 8 | 30 | 2 | |
| ม | 18 | 2 | 4 | 1 | 1 | 21 | 1 | 2 | 23 | 3 | 1 | 3 | 7 | 19 | 5 | |
| เอ็น | 54 | 1 | 2 | 3 | 3 | 34 | 58 | 3 | 1 | 24 | 67 | 2 | ||||
| เกี่ยวกับ | 1 | 28 | 84 | 32 | 47 | 15 | 7 | 18 | 12 | 29 | 19 | 41 | 38 | 30 | 9 | 18 |
| ป | 7 | 15 | 4 | 9 | 1 | 46 | ||||||||||
|
ส่วนที่ 2 |
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ร | กับ | ต | ยู | เอฟ | เอ็กซ์ | ค | ชม | ช | สช | ย | ข | อี | ยุ | ฉัน | |
| ก | 26 | 31 | 27 | 3 | 1 | 10 | 6 | 7 | 10 | 1 | 2 | 6 | 9 | ||
| บี | 8 | 1 | 6 | 1 | 11 | 2 | |||||||||
| ใน | 6 | 19 | 6 | 7 | 1 | 1 | 2 | 4 | 1 | 18 | 1 | 2 | 3 | ||
| ช | 7 | 2 | |||||||||||||
| ดี | 6 | 8 | 1 | 10 | 1 | 1 | 1 | 5 | 1 | 1 | |||||
| อี | 39 | 37 | 33 | 3 | 1 | 8 | 3 | 7 | 3 | 3 | 1 | 1 | 2 | ||
| และ | 1 | ||||||||||||||
| ซี | 3 | 1 | 2 | 4 | 4 | ||||||||||
| และ | 11 | 29 | 29 | 3 | 1 | 17 | 3 | 11 | 1 | 1 | 1 | 3 | 17 | ||
| ย | 3 | 10 | 2 | 1 | 3 | 2 | |||||||||
| ถึง | 10 | 3 | 7 | 10 | 1 | ||||||||||
| ล | 3 | 1 | 6 | 4 | 1 | 3 | 20 | 4 | 9 | ||||||
| ม | 2 | 5 | 3 | 9 | 1 | 2 | 5 | 1 | 1 | 3 | |||||
| เอ็น | 1 | 9 | 9 | 7 | 1 | 5 | 2 | 36 | 3 | 5 | |||||
| เกี่ยวกับ | 43 | 50 | 39 | 3 | 2 | 5 | 2 | 12 | 4 | 3 | 2 | 3 | 2 | ||
| ป | 41 | 1 | 6 | 2 | 2 | ||||||||||
|
ส่วนที่ 3 |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ก | บี | ใน | ช | ดี | อี | และ | ซี | และ | ย | ถึง | ล | ม | เอ็น | เกี่ยวกับ | ป | |
| ร | 55 | 1 | 4 | 4 | 3 | 37 | 3 | 1 | 24 | 3 | 1 | 3 | 7 | 56 | 2 | |
| กับ | 8 | 1 | 7 | 1 | 2 | 25 | 6 | 40 | 13 | 3 | 9 | 27 | 11 | |||
| ต | 35 | 1 | 27 | 1 | 3 | 31 | 1 | 28 | 5 | 1 | 1 | 11 | 56 | 4 | ||
| ยู | 1 | 4 | 4 | 4 | 11 | 2 | 6 | 3 | 2 | 8 | 5 | 5 | 5 | 1 | 5 | |
| เอฟ | 2 | 2 | 2 | 1 | ||||||||||||
| เอ็กซ์ | 4 | 1 | 4 | 1 | 3 | 1 | 2 | 3 | 4 | 3 | 3 | 4 | 18 | 5 | ||
| ค | 3 | 7 | 10 | 2 | 1 | |||||||||||
| ชม | 12 | 23 | 13 | 2 | 6 | |||||||||||
| ช | 5 | 11 | 14 | 1 | 2 | 2 | 2 | |||||||||
| สช | 3 | 8 | 6 | 1 | ||||||||||||
| ย | 1 | 9 | 1 | 3 | 12 | 2 | 4 | 7 | 3 | 6 | 6 | 3 | 2 | 10 | ||
| ข | 2 | 4 | 1 | 1 | 2 | 2 | 2 | 6 | 3 | 13 | 2 | 4 | ||||
| อี | 1 | 1 | ||||||||||||||
| ยุ | 2 | 1 | 2 | 1 | 3 | 1 | 1 | 1 | 1 | 1 | 3 | |||||
| ฉัน | 1 | 3 | 9 | 1 | 3 | 3 | 1 | 5 | 3 | 2 | 3 | 3 | 4 | 6 | 3 | 6 |
|
ตอนที่ 4 |
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ร | กับ | ต | ยู | เอฟ | เอ็กซ์ | ค | ชม | ช | สช | ย | ข | อี | ยุ | ฉัน | |
| ร | 1 | 5 | 9 | 16 | 1 | 1 | 1 | 2 | 8 | 3 | 5 | ||||
| กับ | 4 | 11 | 82 | 6 | 1 | 1 | 2 | 2 | 1 | 8 | 17 | ||||
| ต | 26 | 18 | 2 | 10 | 1 | 11 | 21 | 4 | |||||||
| ยู | 7 | 14 | 7 | 1 | 8 | 3 | 2 | 9 | 1 | ||||||
| เอฟ | 1 | 1 | |||||||||||||
| เอ็กซ์ | 3 | 4 | 2 | 2 | 1 | 1 | |||||||||
| ค | 1 | 1 | |||||||||||||
| ชม | 7 | 1 | 1 | 1 | |||||||||||
| ช | 1 | 1 | |||||||||||||
| สช | 1 | ||||||||||||||
| ย | 3 | 9 | 4 | 1 | 16 | 1 | 2 | ||||||||
| ข | 1 | 11 | 3 | 1 | 4 | 1 | 3 | 1 | |||||||
| อี | 1 | 9 | |||||||||||||
| ยุ | 1 | 1 | 7 | 1 | 1 | 4 | |||||||||
| ฉัน | 3 | 6 | 10 | 2 | 1 | 4 | 1 | 1 | 1 | 1 | 1 | ||||

ตารางที่ดี เค-gram ง่ายต่อการรับโดยใช้ข้อความในเวอร์ชันอิเล็กทรอนิกส์ของหนังสือหลายเล่มที่อยู่ในซีดี
หากต้องการข้อมูลที่แม่นยำยิ่งขึ้นเกี่ยวกับข้อความธรรมดา คุณสามารถสร้างและวิเคราะห์ตารางได้ เค- กรัมที่ เค>2 แต่เพื่อวัตถุประสงค์ทางการศึกษา ก็เพียงพอแล้วที่จะจำกัดตัวเองให้ใช้บิ๊กแกรม ความไม่สม่ำเสมอ เค-gram (และแม้แต่คำ) มีความสัมพันธ์อย่างใกล้ชิดกับคุณลักษณะเฉพาะของข้อความเปิด - การมีอยู่ของการซ้ำซ้อนของส่วนของข้อความแต่ละส่วนจำนวนมาก: ราก, การลงท้าย, คำต่อท้าย, คำและวลี ดังนั้นสำหรับภาษารัสเซีย ชิ้นส่วนที่คุ้นเคยนั้นเป็นบิ๊กแกรมและไตรแกรมที่พบบ่อยที่สุด:
ST, แต่, EN, ถึง, NA, OV, NI, RA, VO, KO
STO, ENO, พ.ย., TOV, OVO, OVA
ข้อมูลเกี่ยวกับความเข้ากันได้ของตัวอักษร ซึ่งก็คือ การเชื่อมต่อตัวอักษรที่ต้องการระหว่างกันนั้นมีประโยชน์ ซึ่งสามารถหาได้ง่ายจากตารางความถี่บิ๊กแกรม
นี่หมายถึงตารางที่ "เพื่อนบ้าน" ที่ต้องการมากที่สุดตั้งอยู่ทางซ้ายและขวาของตัวอักษรแต่ละตัว (ตามลำดับความถี่ของบิ๊กแกรมที่สอดคล้องกันจากมากไปหาน้อย) ตารางดังกล่าวมักจะระบุสัดส่วนของสระและพยัญชนะ (เป็นเปอร์เซ็นต์) ที่อยู่ข้างหน้า (หรือตามหลัง) ตัวอักษรที่กำหนด
การรวมกันของตัวอักษรรัสเซีย:
| ช | กับ | ซ้าย | ด้านขวา | ช | กับ | |
|---|---|---|---|---|---|---|
| 3 | 97 | l, d, k, t, v, r, n | ก | l, n, s, t, r, v, k, m | 12 | 88 |
| 80 | 20 | ฉัน, อี, ย, ฉัน, ก, โอ | บี | o, s, e, a, r, y | 81 | 19 |
| 68 | 32 | ฉัน, t, a, e, ฉัน, o | ใน | o, a, i, s, s, n, l, r | 60 | 40 |
| 78 | 22 | r, y, a, i, e, o | ช | o, a, p, l, i, v | 69 | 31 |
| 72 | 28 | r, ฉัน, y, a, ฉัน, e, o | ดี | e, a, i, o, n, y, p, v | 68 | 32 |
| 19 | 81 | ม, ฉัน, ล, ง, t, r, n | อี | n, t, r, s, l, v, m, i | 12 | 88 |
| 83 | 17 | r, e, i, a, y, o | และ | จ, ฉัน, ง, ก, n | 71 | 29 |
| 89 | 11 | o, e, a และ | ซี | ก n ค โอ ม ง | 51 | 49 |
| 27 | 73 | r, t, m, ฉัน, o, l, n | และ | s, n, c, i, e, m, k, h | 25 | 75 |
| 55 | 45 | b, v, e, o, a, i, s | ถึง | o, a, ฉัน, p, y, t, l, e | 73 | 27 |
| 77 | 23 | g, v, s, ฉัน, e, o, a | ล | ฉัน, e, o, a, b, ฉัน, yu, y | 75 | 25 |
| 80 | 20 | ฉัน, s, a, ฉัน, e, o | ม | ฉัน, e, o, y, a, n, p, s | 73 | 27 |
| 55 | 45 | ง, ข, n, โอ | เอ็น | o, a, i, e, s, n, y | 80 | 20 |
| 11 | 89 | r, p, k, v, t, n | เกี่ยวกับ | ค, s, t, r, ฉัน, d, n, ม | 15 | 85 |
| 65 | 35 | ใน, ด้วย, y, a, i, e, o | ป | o, p, e, a, y, i, l | 68 | 32 |
| 55 | 45 | ฉัน, k, t, a, p, o, e | ร | ก อี โอ ฉัน ย ฉัน ส n | 80 | 20 |
| 69 | 31 | s, t, v, a, e, i, o | กับ | t, k, o, ฉัน, e, b, s, n | 32 | 68 |
| 57 | 43 | h, y, i, a, e, o, s | ต | o, a, e, i, b, v, r, s | 63 | 37 |
| 15 | 85 | p, t, k, d, n, m, r | ยู | t, p, s, d, n, y, w | 16 | 84 |
| 70 | 30 | n, a, e, o และ | เอฟ | และ e, o, a, e, o, a | 81 | 19 |
| 90 | 10 | y, e, o, a, s และ | เอ็กซ์ | o, i, s, n, v, p, r | 43 | 57 |
| 69 | 31 | e, yu, n, a และ | ค | ฉัน, อี, ก, ส | 93 | 7 |
| 82 | 18 | จ, ก, ย, ฉัน, โอ | ชม | จ, ฉัน, t, n | 66 | 34 |
| 67 | 33 | b, y, s, e, o, a, i, v | ช | e, i, n, a, o, l | 68 | 32 |
| 84 | 16 | จ, ข, ก, ฉัน, ย | สช | อี ฉัน ก | 97 | 3 |
| 0 | 100 | ม.ร.ต.ส.ข.ค.น | ย | l, x, e, m, i, v, s, n | 56 | 44 |
| 0 | 100 | n, s, t, l | ข | n, k, v, p, s, e, o และ | 24 | 76 |
| 14 | 86 | s, s, m, l, d, t, r, n | อี | n, t, r, s, k | 0 | 100 |
| 58 | 42 | ข, โอ, ก, ฉัน, ล, ย | ยุ | d, t, sch, c, n, p | 11 | 89 |
| 43 | 57 | o, n, r, l, a, i, s | ฉัน | ค, s, t, p, d, k, m, l | 16 | 84 |

เมื่อวิเคราะห์ความเข้ากันได้ของตัวอักษรระหว่างกันเราควรคำนึงถึงการพึ่งพาลักษณะของตัวอักษรในข้อความธรรมดากับตัวอักษรก่อนหน้าจำนวนมาก ในการวิเคราะห์รูปแบบเหล่านี้ จะใช้แนวคิดเรื่องความน่าจะเป็นแบบมีเงื่อนไข
การสังเกตข้อความธรรมดาแสดงให้เห็นว่าความไม่เท่าเทียมกันต่อไปนี้ถือเป็นความน่าจะเป็นแบบมีเงื่อนไข: พี(ก i1)≠พี(ก i1 /a i2), p(ก i1 /a i2)≠p(ก i1 /a i2 และ i3),....
คำถามเกี่ยวกับการพึ่งพาตัวอักษรของตัวอักษรในข้อความธรรมดากับตัวอักษรก่อนหน้านี้ได้รับการศึกษาอย่างเป็นระบบโดยนักคณิตศาสตร์ชาวรัสเซียชื่อดัง A. A. Markov (1856 - 1922) เขาพิสูจน์ว่าการเกิดขึ้นของตัวอักษรในรูปแบบข้อความธรรมดาไม่สามารถถือว่าเป็นอิสระจากกัน ในเรื่องนี้ A. A. Markov ตั้งข้อสังเกตอีกรูปแบบหนึ่งของข้อความเปิดที่เกี่ยวข้องกับการสลับสระและพยัญชนะ เขาคำนวณความถี่ของการเกิดสระใหญ่ - สระ ( ช, ช) สระพยัญชนะ ( ช, กับ) พยัญชนะ-สระ ( กับ, ช) พยัญชนะพยัญชนะ ( กับ, กับ) ในข้อความภาษารัสเซียที่มีความยาว 10 5 ตัวอักษร ผลการคำนวณจะแสดงในตารางต่อไปนี้:
| ช | กับ | ทั้งหมด | |
|---|---|---|---|
| ช | 6588 | 38310 | 44898 |
| กับ | 38296 | 16806 | 55102 |
จากตารางนี้จะเห็นได้ว่าภาษารัสเซียมีลักษณะเฉพาะด้วยการสลับสระและพยัญชนะและความถี่สัมพัทธ์สามารถใช้เป็นค่าประมาณของความน่าจะเป็นแบบมีเงื่อนไขและไม่มีเงื่อนไขที่สอดคล้องกัน:
พี(ช/กับ)≈0.663, พี(กับ/ช)≈0.872,
พี(ช)≈0.432, พี(กับ)≈0.568.
หลังจาก A. A. Markov การพึ่งพาการปรากฏตัวของตัวอักษรในข้อความหลังจากหลายข้อความก่อนหน้านี้ได้รับการศึกษาโดยวิธีทฤษฎีสารสนเทศโดย K. Shannon ในความเป็นจริงพวกเขาแสดงให้เห็นโดยเฉพาะอย่างยิ่งว่าการพึ่งพาอาศัยกันดังกล่าวจะสังเกตเห็นได้ชัดเจนที่ความลึกประมาณ 30 อักขระหลังจากนั้นก็หายไปในทางปฏิบัติ
สัดส่วนของสระในข้อความวรรณกรรม:

รูปแบบข้างต้นใช้กับข้อความธรรมดาที่ "อ่านได้" ธรรมดาที่ใช้ในการสื่อสารของมนุษย์ ตามที่ระบุไว้ก่อนหน้านี้ รูปแบบเหล่านี้มีบทบาทสำคัญในการเข้ารหัสลับ โดยเฉพาะอย่างยิ่งจะใช้ในการสร้างเกณฑ์ที่เป็นทางการสำหรับข้อความธรรมดาซึ่งทำให้สามารถใช้วิธีการทางสถิติทางคณิตศาสตร์ในปัญหาการรับรู้ข้อความธรรมดาในสตรีมข้อความ เมื่อใช้ตัวอักษรพิเศษ จำเป็นต้องมีการศึกษาลักษณะความถี่ของ "ข้อความเปิด" ที่คล้ายกันที่เกิดขึ้น เช่น ในระหว่างการแลกเปลี่ยนข้อมูลระหว่างเครื่องกับเครื่องหรือในระบบการส่งข้อมูล ในกรณีเหล่านี้ การสร้างเกณฑ์อย่างเป็นทางการสำหรับ "ข้อความที่ชัดเจน" เป็นงานที่ยากกว่ามาก
ตัวอย่างเช่น เราให้ลักษณะความถี่ของตัวอักษรของตัวอักษรภาษาอังกฤษที่เป็นส่วนหนึ่งของรหัส ASCII
นอกจากการเข้ารหัสแล้ว ลักษณะความถี่ของข้อความที่ชัดเจนยังถูกนำมาใช้ในด้านอื่นๆ อีกด้วย ตัวอย่างเช่นแป้นพิมพ์คอมพิวเตอร์เครื่องพิมพ์ดีดหรือ Linotype เป็นศูนย์รวมที่ยอดเยี่ยมของแนวคิดในการเร่งความเร็วการพิมพ์ซึ่งเกี่ยวข้องกับการเพิ่มประสิทธิภาพการจัดเรียงตัวอักษรของตัวอักษรที่สัมพันธ์กันขึ้นอยู่กับความถี่ในการใช้งาน
วรรณกรรม:
อัลเฟรอฟ เอ.พี. และคณะ "วิทยาการเข้ารหัสลับ"
Yaglom A.M., Yaglom I.M., ความน่าจะเป็นและข้อมูล, M.: Nauka, 1973
Baudouin C. องค์ประกอบของการเข้ารหัส / Ed. เปโดน เอ. – ปารีส, 1939.
ฟรีดแมน W. F. , Callimahos D. , การเข้ารหัสทางทหาร, ตอนที่ 1, เล่ม 2, สำนักพิมพ์ Aegean Park, Laguna Hills CA, 1920

พาย “ให้พวกเขากินเค้ก”
วัตถุดิบ:
อัลมอนด์บด 2 ออนซ์
แป้งที่เลี้ยงตัวเอง 6 ออนซ์
ผงฟู 2 ช้อนชา
4 ออนซ์น้ำตาลมัสโควาโดเบา ๆ
น้ำมันข้าวโพด 150 มล.
นมถั่วเหลือง 200–250 มล.
ผิวเลมอนที่ไม่ได้เคลือบสองลูก
น้ำผลไม้จากมะนาวสองลูก
น้ำดอกส้มกลิ่น 1 ช้อนโต๊ะ
สารสกัดวานิลลาธรรมชาติ 1 ช้อนชา
เปิดเตาอบที่ 190 องศาหรือน้อยกว่าหากเตาอบเป็นแบบพัดลม
อัดจาระบีกระทะพาย กระทะลึก 6 นิ้วดีที่สุด แต่กระทะแบบไหนก็ใช้ได้
ใส่แป้งและผงฟูลงในชาม จากนั้นใส่น้ำตาล ผสมอัลมอนด์ป่นและผิวเลมอนลงไป เพิ่มเนยและนม ยิ่งของเหลวน้อยลง จานก็จะมีลักษณะเหมือนพายมากกว่าพุดดิ้งมากขึ้น คุณไม่จำเป็นต้องตวงของเหลวด้วยความแม่นยำ 100% สำหรับเค้กนี้
ตอนนี้เติมน้ำมะนาวและคนให้เข้ากัน เติมน้ำดอกไม้และสารสกัดวานิลลา คนอีกครั้ง ผลลัพธ์ควรมีลักษณะเป็นแป้งหนาและปราศจากยีสต์
เทลงในพิมพ์แล้วนำเข้าเตาอบประมาณสี่สิบนาที เปลือกควรเป็นสีน้ำตาลและไส้นิ่มมาก นำออกจากพิมพ์ พักให้เย็น และตกแต่งด้วยใบสะระแหน่สดและสตรอเบอร์รี่
ตัวอักษรที่พบบ่อยที่สุดในตัวอักษรรัสเซียสามารถเรียกได้อย่างปลอดภัยว่า "o" ไม่ใช่ “a” แม้ว่าเด็กทุกคนจะเรียนรู้คำศัพท์แรกของตนเองด้วยตัวอักษรนี้: “แม่” “พ่อ” หรือ “ให้” ไม่ใช่ “และ” แม้ว่าอาจดูเหมือนว่าเรามักใช้มันเป็นคำเชื่อมที่เชื่อมโยงกันก็ตาม
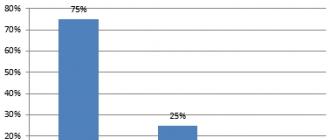
จากข้อมูลพบว่าเป็นตัวอักษร “o” ที่มีความถี่เกิน 0.1% เทียบกับอักษรสระตัวอื่นๆ ที่มีความถี่ เช่น 0.07-0.08% ซึ่งถือว่าค่อนข้างมาก
ในบรรดาพยัญชนะนั้น ตัวอักษร "n" มาก่อน
ข้อมูลดังกล่าวได้มาจากการวิเคราะห์ความถี่ใน NCRY - National Corpus ของภาษารัสเซียโดยใช้สูตรพิเศษ NKRY เป็นคลังข้อความอิเล็กทรอนิกส์ที่เป็นลายลักษณ์อักษรและคำพูด ซึ่งประกอบด้วยการใช้คำประมาณ 230 ล้านคำ
เมื่อพิจารณาถึงตัวอักษรที่ได้รับความนิยมมากที่สุดในตัวอักษรของเราก็ควรค่าแก่การกล่าวถึงปรากฏการณ์ที่น่าสนใจที่เรียกว่า "tautogram" นี่เป็นการอุ่นเครื่องวรรณกรรมที่คุณต้องเขียนเรื่องราวหรือบทกวีโดยขึ้นต้นด้วยตัวอักษรเดียวกัน อย่างไรก็ตามตัวอักษรที่คำส่วนใหญ่ในภาษารัสเซียขึ้นต้น (อย่าสับสนกับความถี่ในการใช้งาน) คือ "p" แต่ในบรรดาสระนั้นความเป็นผู้นำที่ไม่ต้องสงสัยนั้นเป็นของโปรดของเราในปัจจุบัน
"ตามลำพัง. มาก. เศษเสี้ยวของเสน่ห์หลุดลอยไปในความน่าเบื่อหน่ายในฤดูใบไม้ร่วง โอลิมปัสยังคงเป็นทางออกที่ห่างไกล ห่างไกลมาก ความแค้นยังคงอยู่ คำจำกัดความผื่นของการละลายที่ละลายแล้ว เกิดจากไฟแห่งการสัมผัส ที่เหลือกลับกลายเป็นแง่ลบ ถูกปฏิเสธ ถูกสังคมหลอก ลูกหลานแห่งฤดูใบไม้ร่วงสะดุดและบินไปรอบ ๆ พร้อมกับเศษดวงตาของทะเลสาบ หน้าต่างบางบานยังคงเปิดอยู่ รอยประทับอันโกรธเกรี้ยวของคำพ้องเสียงของแต่ละบุคคลถูกบดบังด้วยเสื้อคลุมที่ถูกปฏิเสธของตัวตน เฉดสีส้มของทะเล buckthorn นั้นสะท้อนถึงความเหงาครั้งใหญ่ ที่เหลือคือขบวนการสร้างกระดูก ความชาแห่งหายนะ หมู่เกาะนี้เต็มไปด้วยคำสาบานจากบทความเรื่องความแน่นอน การตัดออลเดอร์ที่เย็นลงก่อตัวเป็นวงกลมที่มีชื่อเดียวกัน เนื่องจากมีเสียงแหบแห้ง เจ้าหน้าที่กลายเป็นภาพสะท้อนของนายพลโดยยกเลิกความเชื่อมั่นเชิงลบ ภาพที่ตัดสินอย่างไม่พอใจอธิบายเรื่องไร้สาระในฤดูใบไม้ร่วงโดยเรียกสิ่งที่ตรงกันข้ามว่าเป็นการหลอกลวง เด็กๆ กล่าวถึงฤดูใบไม้ร่วงอันน่าหลงใหลนี้อย่างหมดหวัง โดยปฏิเสธทัศนคติที่ไม่เป็นกลาง... ฤดูใบไม้ร่วงบินไปรอบๆ ราวกับเศษส้มของทะเล buckthorn ทิ้งความขัดแย้งอันเหนื่อยล้าไว้กับคำตอบอันโดดเดี่ยว..."
มันตลกใช่มั้ย? มันไม่ใช่เรื่องไร้สาระเลย :)
โดยวิธีการในภาษาอังกฤษตัวอักษรที่พบบ่อยที่สุดคือ "e" และพยัญชนะคือ "t"
และรูปสัญลักษณ์เป็นภาษาอังกฤษ:
แมรี่ผู้สง่างามที่มีรูปร่างเหมือนมิเนอร์วาเคลื่อนไหว
กฎหมาย ละติน เสรีภาพ เรียนรู้ว่าลูซี่รัก
ความสง่างามของเอลิซ่าแต่ละสายตาสอดส่อง
รอยยิ้มของซูซานที่เงียบเงียบอย่างสงบทำให้ประหลาดใจ
จากคนโง่ คนโง่ คำเยินยอ แฟนนี่ที่สวยที่สุดบินได้
ความถี่ของการใช้ตัวอักษรในภาษารัสเซียคุณรู้หรือไม่ว่าตัวอักษรบางตัวพบในคำต่างๆ บ่อยกว่าตัวอักษรอื่นๆ... นอกจากนี้ความถี่ในการใช้สระในภาษายังสูงกว่าพยัญชนะอีกด้วย
ตัวอักษรใดของอักษรรัสเซียที่พบบ่อยที่สุดหรือน้อยที่สุดในคำที่ใช้เขียนข้อความ?
สถิติเกี่ยวข้องกับการระบุและการศึกษารูปแบบทั่วไป ด้วยความช่วยเหลือของทิศทางทางวิทยาศาสตร์นี้ คุณสามารถตอบคำถามข้างต้นได้โดยการนับจำนวนตัวอักษรแต่ละตัวในตัวอักษรรัสเซีย คำที่ใช้ และเลือกข้อความที่ตัดตอนมาจากผลงานของผู้เขียนหลายคน เพื่อประโยชน์ของตนเองและเพื่อทำบางสิ่งบางอย่างให้หายเบื่อ ทุกคนสามารถทำได้ด้วยตนเอง ฉันจะอ้างอิงถึงสถิติของการศึกษาที่ดำเนินการไปแล้ว...

ตัวอักษรรัสเซียซีริลลิก ในระหว่างที่ดำรงอยู่มีการปฏิรูปหลายครั้งอันเป็นผลมาจากระบบตัวอักษรรัสเซียสมัยใหม่ซึ่งรวมถึงตัวอักษร 33 ตัวที่ถูกสร้างขึ้น

โอ — 9.28%
เอ — 8.66%
อี — 8.10%
และ - 7.45%
ไม่มี — 6.35%
เสื้อ — 6.30%
พี — 5.53%
ส — 5.45%
ลิตร - 4.32%
ใน — 4.19%
เค — 3.47%
n — 3.35%
ม. — 3.29%
ใช่ - 2.90%
ง — 2.56%
ฉัน - 2.22%
ส — 2.11%
ข — 1.90%
ซี — 1.81%
ข — 1.51%
กรัม — 1.41%
ธ - 1.31%
ชั่วโมง — 1.27%
คุณ — 1.03%
x — 0.92%
ฉ — 0.78%
w — 0.77%
ค — 0.52%
กำหนด — 0.49%
ฉ — 0.40%
อี — 0.17%
ก — 0.04%
ตัวอักษรรัสเซียที่มีความถี่ในการใช้งานสูงสุดคือสระ” เกี่ยวกับ"ดังที่ได้เสนอแนะไว้อย่างถูกต้องแล้ว ณ ที่นี้ นอกจากนี้ยังมีตัวอย่างทั่วไปเช่น “ ป้องกัน"(7 ชิ้นในคำเดียวและไม่มีอะไรแปลกใหม่หรือน่าประหลาดใจ เป็นเรื่องธรรมดามากสำหรับภาษารัสเซีย) ความนิยมอย่างสูงของตัวอักษร "O" นั้นส่วนใหญ่อธิบายได้จากปรากฏการณ์ทางไวยากรณ์เช่นสระเต็ม นั่นคือ "เย็น" แทนที่จะเป็น "เย็น" และ "น้ำค้างแข็ง" แทนที่จะเป็น "ขยะ"
และที่จุดเริ่มต้นของคำมักพบตัวอักษรพยัญชนะ "" ป" ความเป็นผู้นำนี้ยังมีความมั่นใจและไม่มีเงื่อนไข เป็นไปได้มากว่าคำอธิบายนั้นมาจากคำนำหน้าจำนวนมากที่ขึ้นต้นด้วยตัวอักษร "P": pere-, pre-, pre-, pri-, pro- และอื่น ๆ
ความถี่ของการใช้ตัวอักษรเป็นพื้นฐานของการเข้ารหัส
โดยทั่วไปมีหัวข้อดังกล่าว - การวิเคราะห์ความถี่ของข้อความ เป็นที่ถกเถียงกันอยู่ว่าสำหรับภาษาหนึ่งๆ ความถี่ของการเกิดตัวอักษรแต่ละตัวในข้อความที่มีความหมายนั้นเป็นค่าคงที่ การผสมระหว่างสอง, สาม (ไดแกรม, ไตรแกรม) และตัวอักษรสี่ตัวก็มีเสถียรภาพเช่นกัน
โดยเฉพาะอย่างยิ่งข้อเท็จจริงนี้ถูกนำมาใช้ในการเข้ารหัสเพื่อทำลายรหัส
ฉันไม่เก่งเรื่องการเข้ารหัส และสิ่งเดียวที่อยู่ในใจคือทำลายรหัสแทนที่โดยตรง ต้องบอกว่ารหัสดั้งเดิมที่สุดคือเมื่ออักขระของตัวอักษรต้นฉบับที่ใช้ในข้อความถูกแปลงเป็นอักขระอื่นตามกฎบางอย่าง อย่างไรก็ตาม ยันต์ดังกล่าวสามารถเปิดได้โดยไม่ต้องใช้การวิเคราะห์ทางสถิติ (โดยที่เห็นได้ชัดว่าต้องมีข้อความค่อนข้างใหญ่เพื่อลดข้อผิดพลาด) แต่เพียงแค่เดาคำบางคำ - ดูเรื่องราว“ The ผู้ชายเต้นรำ”.
และสัมผัสสุดท้าย (ไม่จำเป็น) บางครั้ง (เกือบทุกครั้งในตอนนี้) เครื่องคิดเลขจำเป็นต้องมีคำอธิบาย เช่น พารามิเตอร์คืออะไร สูตรที่ใช้ และโดยทั่วไป ทำไมจึงมีไว้เพื่ออะไร เช่นเดียวกับที่ฉันกำลังทำอยู่ตอนนี้ เมื่อต้องการทำเช่นนี้ มีการเขียนบทความ และเครื่องคิดเลขจะถูกแทรกลงในบทความโดยตรง หากต้องการเขียนบทความ ให้เลือกรายการเมนู "สร้าง..." -> "บทความ" บนหน้าหลักของส่วน "เครื่องคิดเลขของฉัน" และเริ่มเขียน หากต้องการแทรกเครื่องคิดเลข ให้กดปุ่มที่มีตัวอักษร A ที่ขีดเส้นใต้ขนาดใหญ่ และเลือกเครื่องคิดเลขที่สร้างขึ้นใหม่ในช่องโต้ตอบที่เปิดขึ้น